My dqrng package has some quite old issues, one is “More distribution functions” where I brought forward the idea to support additional distribution functions within dqrng, which currently only supports uniform, normal and exponential distributions. I still think this would be a good idea, but it would also be nice if one could simply plug into the large number of distribution functions that have been implemented for R already. Fortunately this is possible via the mechanism described in User-supplied Random Number Generation. In #67 I have implemented this. Let’s see how that works by comparing the performance of runif, rnorm, rexp, and sample.int1 with their counterparts from dqrng with different settings for user-supplied RNGs.
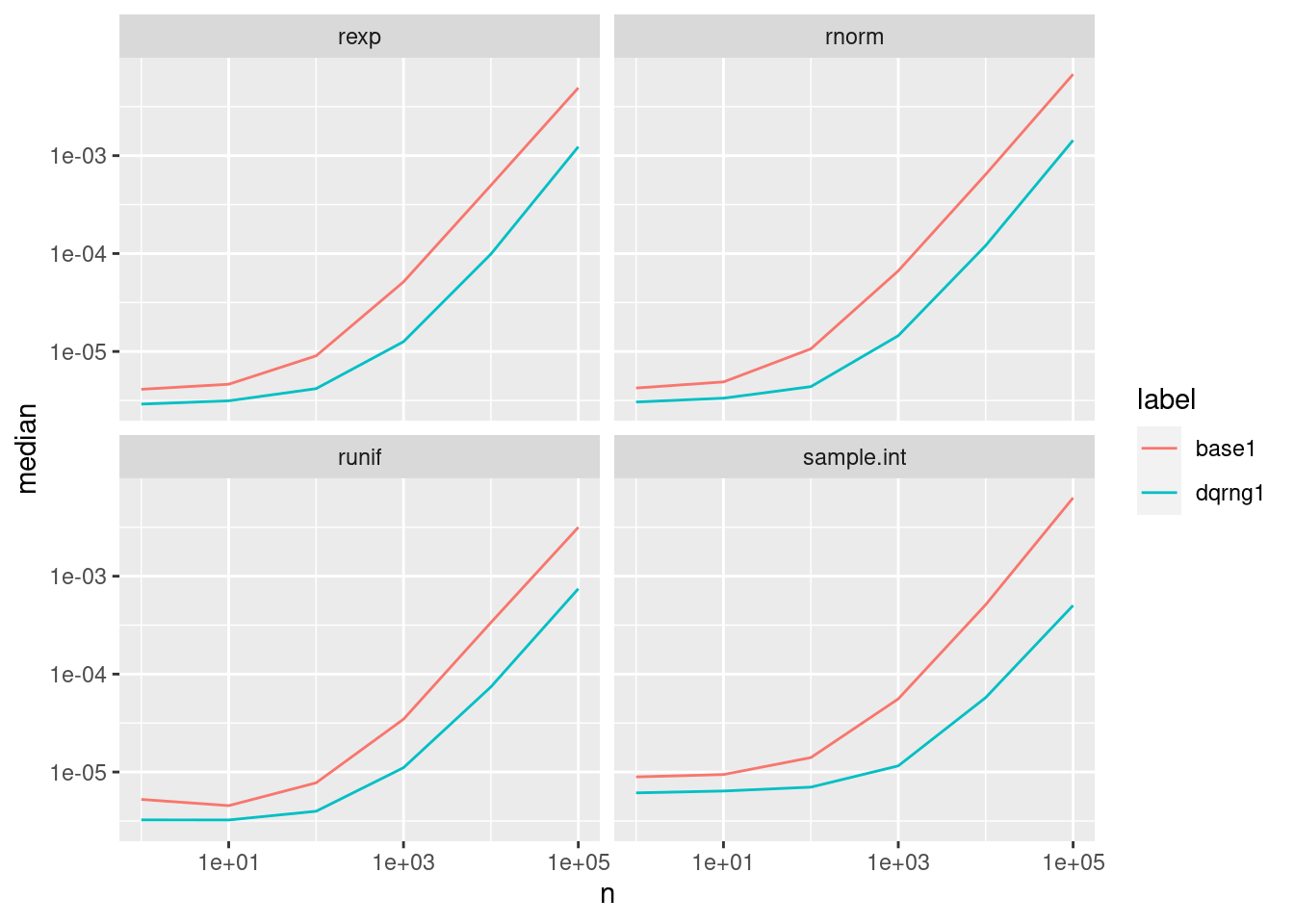
When comparing the default methods from R with those from dqrng we see a consistent performance advantage for the latter with a factor of about 5 for larger samples:
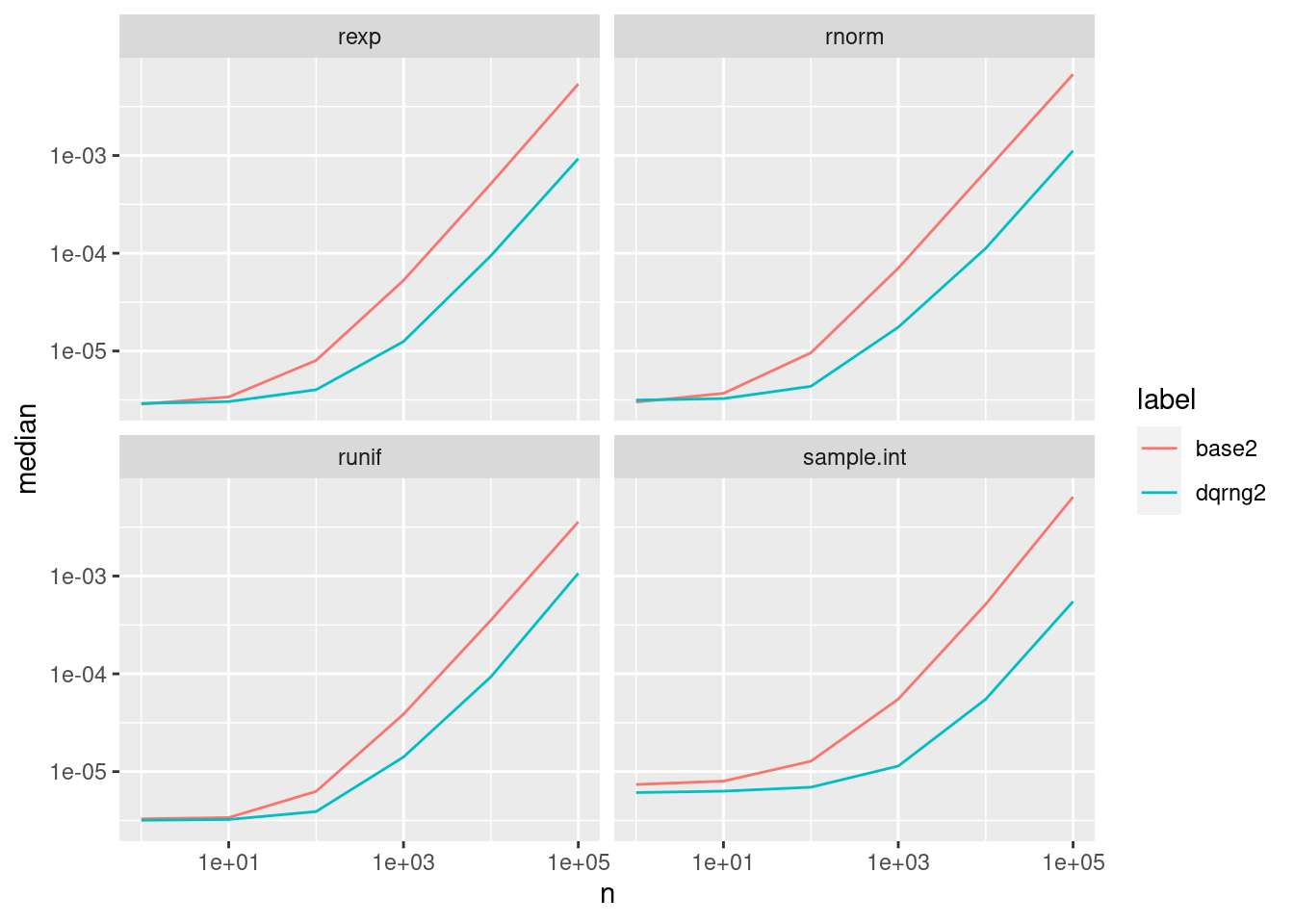
When we enable the RNG from dqrng for the uniform distribution things change for all three distribution functions. For smaller samples of less than 100 draws, the base methods now have comparable performance. Unfortunately, there is not much change for sample.int. For larger samples dqrng still has the edge in all cases, though:
RNGkind("user")
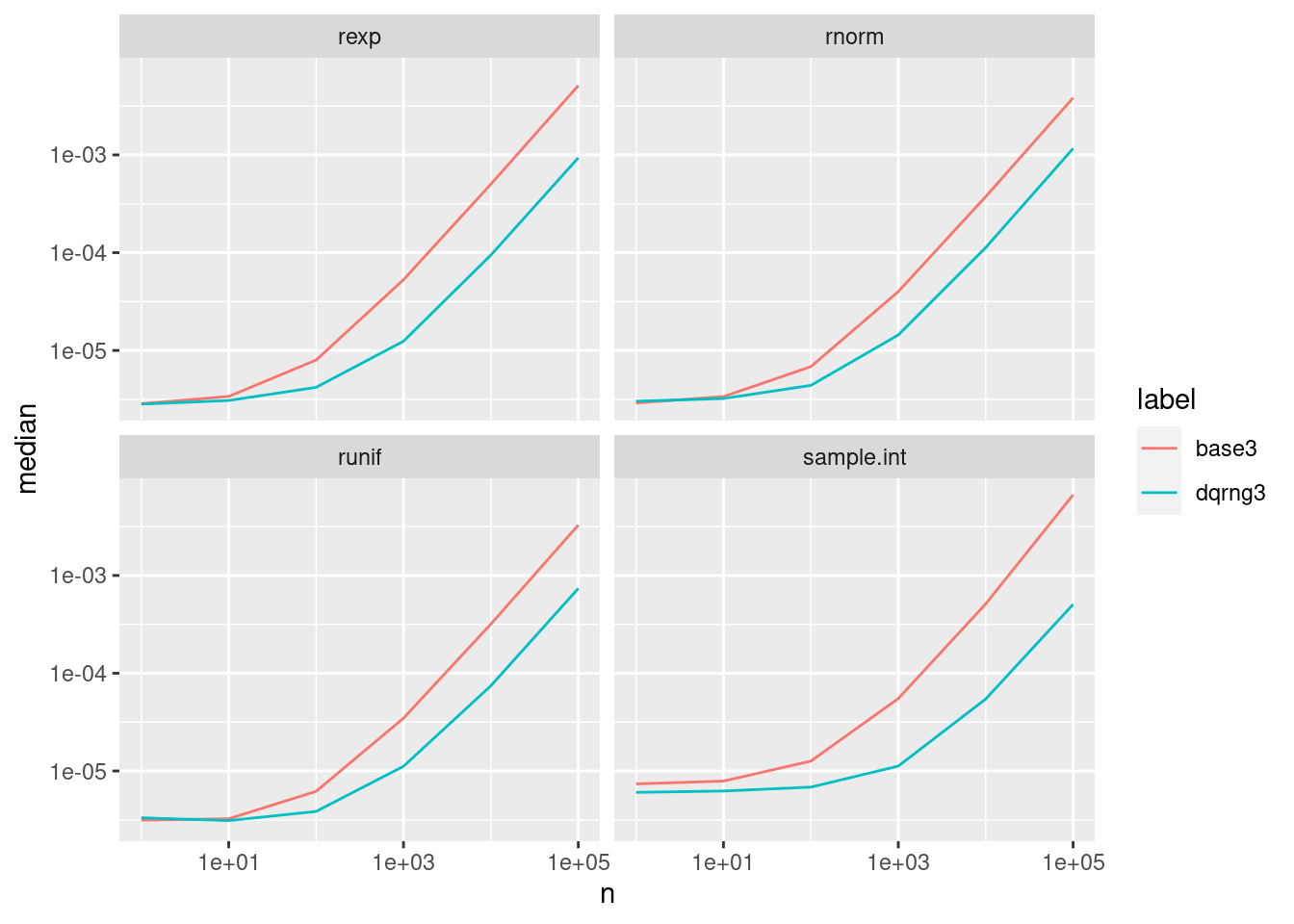
When we also enable the Ziggurat algorithm for normal draws, one sees a nice speedup in rnorm:
RNGkind("user", "user")
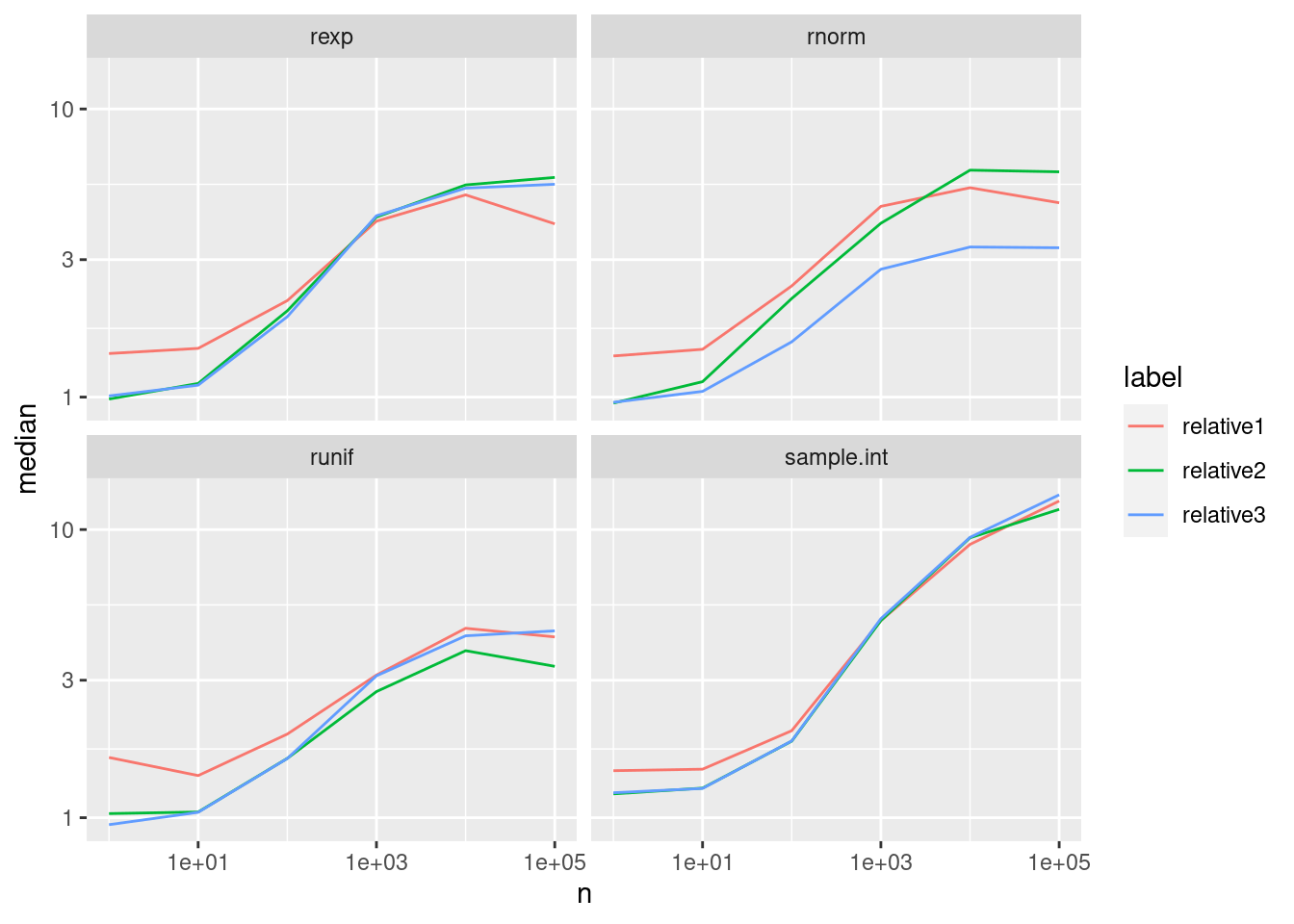
We can also see this when computing the relative speedup of dqrng compared with base R. Enabling the RNG from dqrng for the uniform distribution (“relative2”) brings the base methods on par with their dqrng counterparts for small samples.Also enabling the Ziggurat method for rnorm brings some improvements for larger samples. Unfortunately, there is not much change for sample.int:
But does this help with making more distribution functions available for people using dqrng? Yes! Internally all the distribution functions in R make use the uniform and the normal distribution. And when we replace those with the variants from dqrng, this also influences these distributions. But first of all, we see that we can set the seed with the normal set.seed and get the same reproducible numbers from base or dqrng methods:
The same is true if you use dqset.seed. However, the even with the same input seed a different output is created, since R does some scrambling on the seed before using it. Maybe I should revert that:
But how do we know that this also works for other distributions? We can simply try it out. Do we get reproducible numbers from various distribution functions after using dqset.seed? Yes:
at the top of a script before (potentially) setting the seed with set.seed will give high performance for any random draws without further changes to the code. By replacing runif, rnorm, rexp, and sample.int with their counterparts from dqrng one can gain even more, in particular for larger samples. And maybe in the future more distribution functions will be added to dqrng it sself.
Footnotes
For runif, rnorm, and rexp the default values for the various distribution parameters are used. Similar for sample.int with size == n and replace == FALSE.↩︎